北大联合小鹏汽车发布 FastDriveVLA




北大联合小鹏汽车发布 FastDriveVLA:实现智驾 VLA 高效视觉压缩
在自动驾驶领域,视觉-语言-动作(VLA)模型凭借强大的复杂场景理解与决策能力,正逐渐成为行业焦点。然而,其在处理视觉信息时,会将图像编码为大量视觉token,带来高昂的计算成本与推理延迟,严重阻碍了该技术在资源受限的车载环境中的广泛应用。2025年7月22日,北京大学与小鹏汽车的联合团队JiajunCao、QizheZhang、PeidongJia等研究人员,提出了一种创新的FastDriveVLA框架,通过基于图像复原能力判断视觉token重要性,实现高效的视觉token压缩,为这一难题提供了解决方案。
现有视觉token剪枝方法的局限
当前,为解决VLA模型中视觉token过多的问题,研究主要集中在两个方向的视觉token剪枝策略:一是注意力机制导向方法,依据文本token与视觉token之间的注意力权重筛选。但在驾驶场景中,文本指令往往固定且简短,提供的监督信息有限,导致筛选效果不佳,容易误留大量对驾驶决策无关紧要的背景token。二是相似度导向方法,通过度量视觉token间的冗余度去重。然而,驾驶场景中前景区域(如车道、车辆、行人等)对驾驶决策至关重要,此类方法容易误删关键前景token,保留大量无关背景token,难以满足自动驾驶任务需求。
FastDriveVLA的创新策略
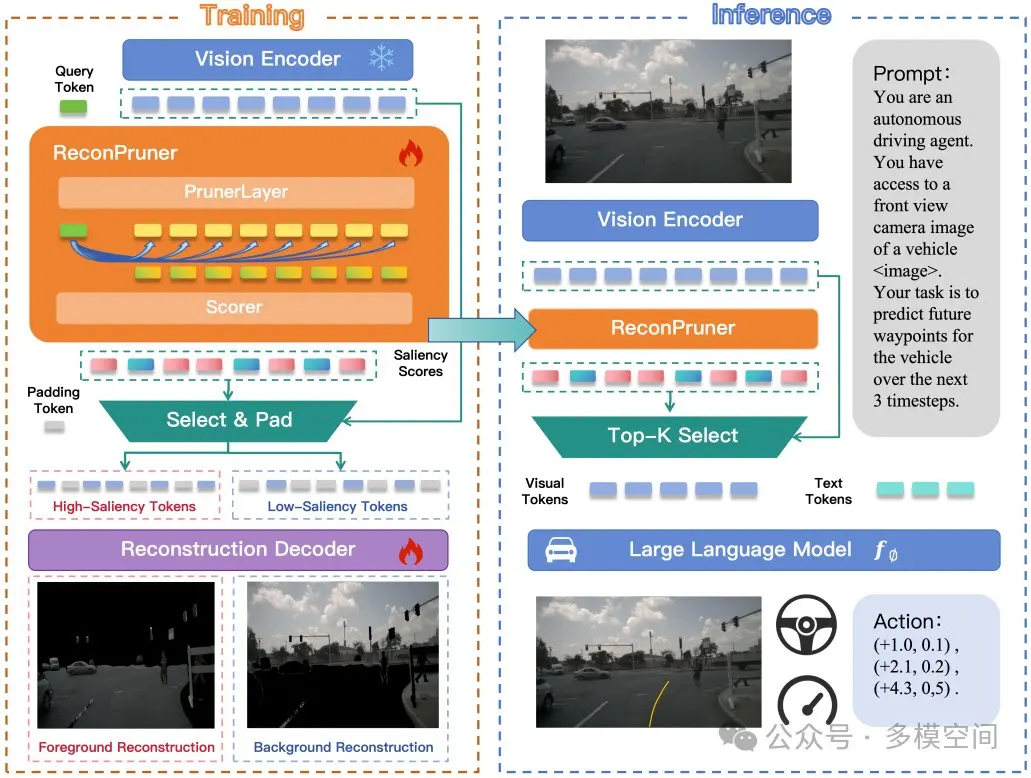
FastDriveVLA的核心思想源于对人类驾驶行为的观察:驾驶员在驾驶时主要关注与决策直接相关的前景区域,背景区域对驾驶决策影响极小。因此,保留编码前景信息的token,就能在保证性能的同时显著降低计算成本。该框架包含一个即插即用的剪枝器ReconPruner,通过MAE风格的像素重建任务进行训练,使模型聚焦于前景区域,为包含关键信息的token赋予更高显著性分数。
在具体操作中,ReconPruner采用Qwen2.5-VL-3B解码层的结构,评估层Scorer则采用其单前馈层结构。ReconPruner将预设querytokens和输入的visualtokens进行互注意力融合,再通过Scorer层给出querytokens中每个token的重要性分值。训练过程中,筛选出的重要visualtokens会基于MAE方式复原前景图像,以此证明其具备支撑场景关键信息感知的能力。
为防止模型为所有visualtokens赋予高重要性分数的“偷懒”行为,团队借鉴生成对抗网络(GAN)思路,引入对抗式前景-背景重建策略:不仅利用高分token重建前景,还强制低分token重建背景,增强模型对前景与背景的区分能力。由于训练涉及二分类前景mask的梯度回传问题,团队采用Bengio在深度学习量化操作中提出的直通式梯度回传(STE)策略解决,确保训练过程的顺利进行。
专用数据集nuScenes-FG的构建
为支持ReconPruner的训练,团队构建了大规模数据集nuScenes-FG。该数据集基于nuScenes数据集,并使用Grounded-SAM进行前景分割标注,涵盖六个车载摄像头视角,共计24.1万张图像-mask对。研究人员将自动驾驶场景中的前景区域明确定义为包含行人、道路、车辆、交通标志和交通障碍物的区域,采用Grounded-SAM生成一致且细粒度的前景分割标注,为ReconPruner的训练提供了高质量的数据支持。
实验验证显著成效
研究团队采用Impromptu-VLA作为视觉token剪枝的基础模型,在nuScenes数据集上展开实验,训练使用2张NVIDIAH800GPU,耗时约3小时,共进行10个epochs。实验结果显示,FastDriveVLA表现卓越:在25%的剪枝比例下,该方法在所有指标上超越现有方法,在L2与碰撞率上甚至超过未剪枝基线;当剪枝比例提升到50%、75%时,模型在保持较高性能的同时,大幅降低了计算量。在效率方面,当视觉token数量从3249条减少至812条时,FastDriveVLA的FLOPs降低约7.5倍;Prefill延迟减少3.7倍;Decode延迟减少1.3倍。可视化结果直观地展示了FastDriveVLA的优势,该方法能精确保留与前景物体相关的token,清晰区分背景区域,在降低token冗余的同时,高质量重建关键视觉信息,相比FastV、DivPrune等方法,对车道区域、车辆和交通标志的关注与保留更加有效。
北大与小鹏汽车联合提出的FastDriveVLA框架,通过创新的基于图像复原的视觉token剪枝策略,有效解决了智驾VLA模型计算成本高的难题,为自动驾驶VLA模型的高效部署开辟了新路径,也为特定任务的剪枝策略研究提供了宝贵思路。

