鹏友们,智驾圈现在玩软件套路,搞懂这几个词,秒变“技术流”不被忽悠~
🔍 端到端(E2E):智驾的“大脑平替”
技术原理:模拟人脑神经元连接,一头输入摄像头等感知的道路信息,另一头直接输出驾驶轨迹或控制信号,跳过传统模块化的“拆分处理”,让信息传递0损耗。
优劣:实现丝滑拟人化驾驶,但出问题难排查,像人脑“抽风”说不清楚哪错。现在车企都能搞模型,但它只是架构,实际效果还得看各家真本事,别盲目吹爆!
🚪 D2D(Door to Door):智驾的“全程马拉松”
技术原理:从出发车位到目标车位,全程自动开,不喊你接管。两派实现逻辑不同:
- 理想派:用“记忆泊车(VPA)+智驾领航(NOA)+VPA”,停车场景靠记忆模式,公路切换智驾领航,擅长高速ETC场景,无需提前“记路线”。
- 特斯拉/小鹏派:一套模式打通全场域,无论园区、公路还是地下车库,始终保持智驾交互画面,场景切换无缝衔接。
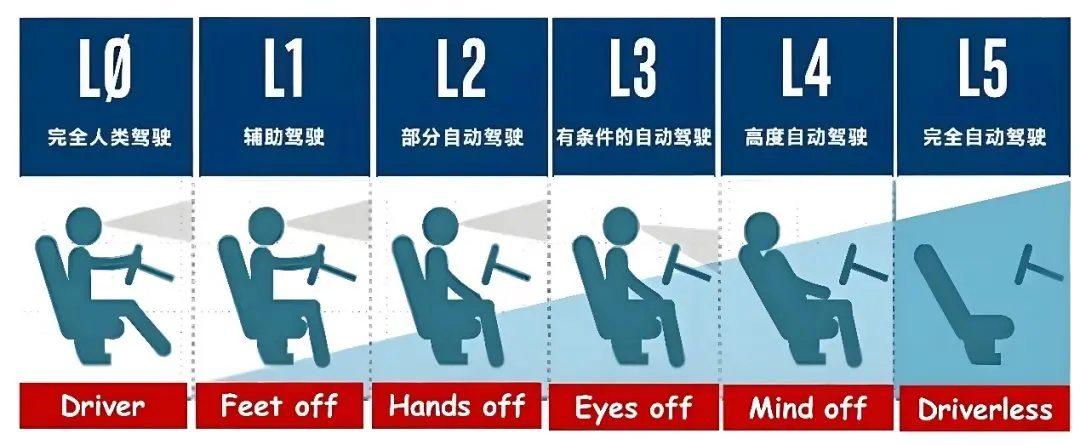
优劣:检验智驾全场景连贯性,但实现难度极高,需接近L3级水平,超耗算法与数据!
🖼️ VLM(视觉语言模型):智驾的“翻译官教练”
技术原理:像会“翻译”的大脑,处理图片、视频等视觉信息,结合语言逻辑理解交通场景(如识别“前方车辆变道”),为驾驶系统提供决策参考,辅助判断“该加速还是避让”。
优劣:让驾驶决策更拟人化,但现阶段占用算力多,功能投入产出比一般,属于过渡技术,等后续优化~
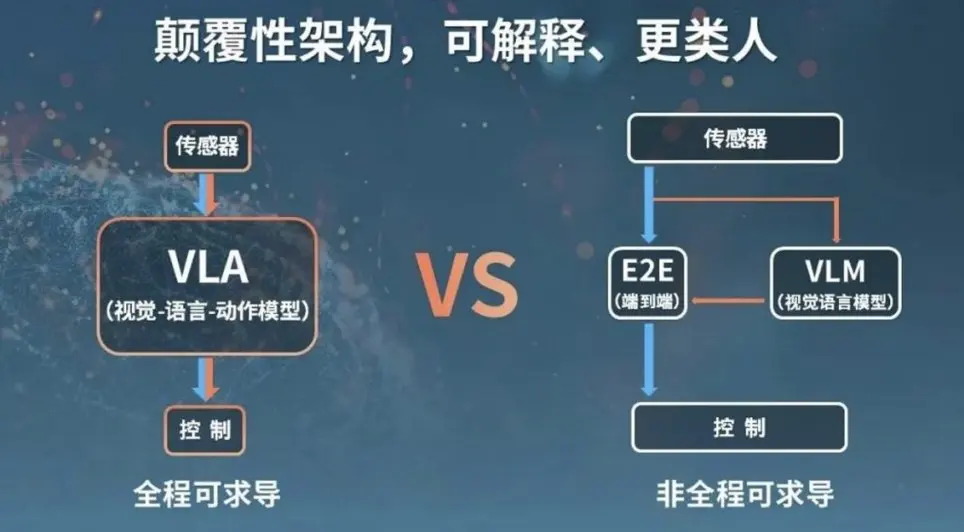
🤖 VLA(视觉-语言-动作模型):智驾的“最强大脑”
技术原理:多模态融合高手!从传感器数据中提取环境信息,借助语言模型理解人类指令,生成可解释的驾驶决策(如分析几十秒路况后推理操作等长时序推理场景),还能将多模态信息转化为具体驾驶指令,实现人类级推理与全局理解。
优劣:推理能力强,系统透明化提升信任度,但超挑硬件:需高算力芯片(如Orin)+企业垂直整合能力,现在车企正拼落地速度,理想、华为等都在卷!
总结:智驾卷体验时代,不同技术路线各有乾坤。搞懂原理与优劣,买车聊智驾不慌,拒绝当韭菜,变身技术流老司机!🚘💥